Introduction to SVM Classifier
Aug 16, 2024
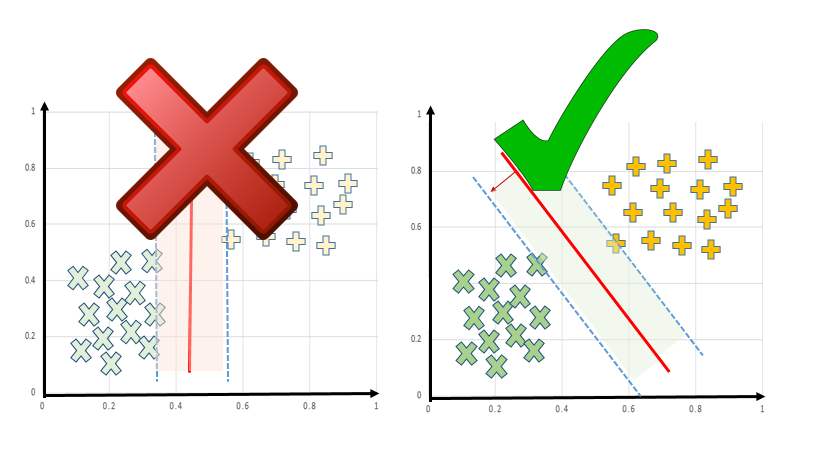
Support Vector Machines (SVMs) are a powerful and versatile machine learning algorithm used for classification and regression tasks. SVM classifiers aim to find the optimal hyperplane that separates different classes of data with the maximum margin. This blog post will dive into the fundamentals of SVM classifiers, explore the different types of SVM kernels, and provide practical examples of implementing SVM in Python.
What is an SVM Classifier?
An SVM classifier is a supervised machine learning model that performs binary or multi-class classification by constructing a hyperplane or set of hyperplanes in a high-dimensional space. The goal is to find the hyperplane that has the largest distance to the nearest training data points of any class, as this will generally result in lower generalization error of the classifier. SVM classifiers are particularly effective when dealing with high-dimensional data, such as text classification, image recognition, and bioinformatics. They can handle both linear and non-linear decision boundaries by using different kernel functions.
Types of SVM Kernels
One of the key advantages of SVM classifiers is their flexibility in handling different types of data and decision boundaries. This flexibility is achieved through the use of kernel functions, which transform the input data into a higher-dimensional feature space. Here are some common types of SVM kernels:
Linear Kernel
The linear kernel is the simplest form of SVM kernel, which is used when the data is linearly separable. It can be expressed as: K(xi,xj)=xiTxj
where $x_i$ and $x_j$ are input vectors.
Polynomial Kernel
The polynomial kernel is used when the decision boundary is non-linear but can be approximated by a polynomial function. It is defined as: K(xi,xj)=(xiTxj+1)d
where $d$ is the degree of the polynomial.
Radial Basis Function (RBF) Kernel
The RBF kernel is a popular choice for non-linear classification tasks. It is defined as: K(xi,xj)=exp(−γ∥xi−xj∥2)
where $\gamma$ is the gamma parameter that controls the width of the Gaussian kernel.
Sigmoid Kernel
The sigmoid kernel is inspired by the activation function used in neural networks. It is defined as: K(xi,xj)=tanh(γxiTxj+r) where $\gamma$ and $r$ are kernel parameters.
Implementing SVM Classifier in Python
Let's dive into a practical example of implementing an SVM classifier in Python using the scikit-learn library. We'll use the popular iris dataset to demonstrate the process.
In this example, we:
Load the iris dataset and split it into training and testing sets.
Create an SVM classifier with the RBF kernel, setting the
Cparameter to 1 andgammato 'auto'.Train the classifier on the training data using the
fit()method.Make predictions on the test set using the
predict()method.Calculate the accuracy score using the
accuracy_score()function from scikit-learn.
The output will show the accuracy of the SVM classifier on the iris dataset.
Advantages and Disadvantages of SVM Classifiers
Advantages:
Effective in high-dimensional spaces and can handle a large number of features.
Memory efficient, as it uses a subset of training points in the decision function (called support vectors).
Versatile, as different kernel functions can be specified for the decision function.
Robust to outliers with proper parameter tuning.
Disadvantages:
Choosing the right kernel function and tuning its parameters can be challenging.
Computationally expensive for large-scale problems, as it involves solving a quadratic optimization problem.
Sensitive to the scale of the input features, so normalization is often necessary.
Primarily designed for binary classification, although it can be extended to multi-class problems.
Conclusion
SVM classifiers are a powerful tool in the machine learning arsenal, offering flexibility, robustness, and high performance in various classification tasks. By understanding the different types of SVM kernels and their applications, you can choose the most suitable kernel for your specific problem. With the help of libraries like scikit-learn, implementing SVM classifiers in Python is straightforward and efficient.
As you continue to explore and apply SVM classifiers, remember to preprocess your data, tune the hyperparameters, and evaluate the model's performance on a separate test set. With practice and experimentation, you'll be able to harness the full potential of SVM classifiers in your machine learning projects.