Introduction to SVM Machine Learning
Aug 16, 2024
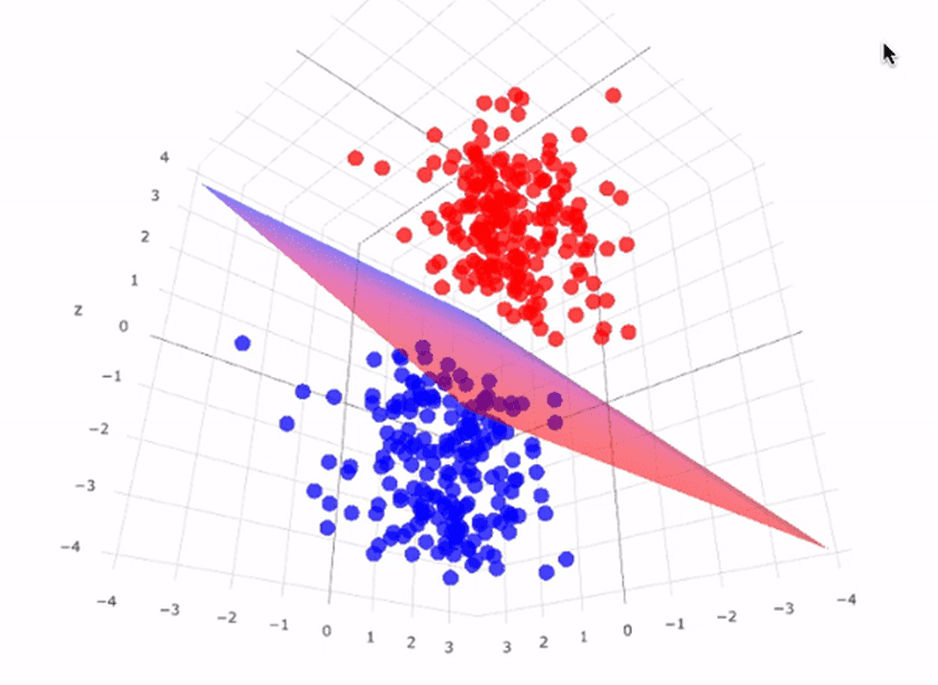
Support Vector Machines (SVMs) are a powerful machine learning algorithm used for both classification and regression tasks. SVM is particularly effective in high-dimensional spaces and works well with a clear margin of separation between classes. In this comprehensive guide, we'll explore the fundamentals of SVM, its types, advantages, and real-world applications.
What is SVM?
SVM is a supervised learning algorithm that analyzes data and recognizes patterns, primarily used for classification and regression analysis. The core idea behind SVM is to find the optimal hyperplane that best separates different classes in the feature space. The hyperplane is chosen to maximize the margin between the closest data points of different classes, known as support vectors.
Types of SVM
There are two main types of SVM: Linear SVM and Non-Linear SVM.
Linear SVM
Linear SVM is used for linearly separable data, where a straight line can be used to separate the classes. The algorithm aims to find the optimal hyperplane that maximizes the margin between the support vectors of different classes.
Here's an example of how to implement Linear SVM in Python using scikit-learn:
Non-Linear SVM
Non-Linear SVM is used for non-linearly separable data, where a straight line cannot separate the classes. In such cases, SVM maps the input data into a higher-dimensional feature space using a kernel function, where the data becomes linearly separable. Common kernel functions include polynomial, radial basis function (RBF), and sigmoid.
Support Vector Regression (SVR)
Support Vector Regression (SVR) is an extension of SVM used for regression tasks. SVR aims to find a function that has at most ε deviation from the actual targets for all the training data, and at the same time is as flat as possible. SVR uses the same principles as SVM, but instead of maximizing the margin, it minimizes the error.
Advantages of SVM
High accuracy: SVM often achieves high accuracy, even with a small training dataset.
Flexibility: SVM can handle a variety of data types, including numerical, text, and vector data.
Kernel trick: SVM uses the kernel trick to efficiently compute the inner product in high-dimensional feature spaces.
Sparsity: SVM models are sparse, meaning they only depend on a subset of the training data (support vectors), making them efficient in memory and computationally.
Disadvantages of SVM
Sensitivity to feature scaling: SVM is sensitive to the scale of the input features, and it's important to scale the data before training the model.
Difficulty in handling large datasets: SVM can be computationally expensive for large datasets, as it requires solving a quadratic programming problem.
Difficulty in handling overlapping classes: SVM may struggle with datasets that have overlapping classes or noisy data.
Applications of SVM
SVM has a wide range of applications in various domains, including:
Image recognition: SVM is used for tasks such as handwriting recognition, facial recognition, and object detection.
Text classification: SVM is effective in classifying text documents into predefined categories, such as spam detection, sentiment analysis, and topic modeling.
Bioinformatics: SVM is used for gene expression data analysis, protein structure prediction, and disease diagnosis.
Finance: SVM is applied in financial time series prediction, credit risk assessment, and fraud detection.
Anomaly detection: SVM can be used to identify anomalies or outliers in data, which is useful in applications such as intrusion detection and fault diagnosis.
Conclusion
Support Vector Machines are a powerful and versatile machine learning algorithm that can handle a wide range of classification and regression tasks. By understanding the fundamentals of SVM, its types, and its applications, you can leverage its capabilities to solve complex problems in various domains. As with any machine learning algorithm, it's essential to preprocess the data, tune the hyperparameters, and evaluate the model's performance to achieve optimal results.