Logistic Regression in Python: A Comprehensive Guide
Aug 17, 2024
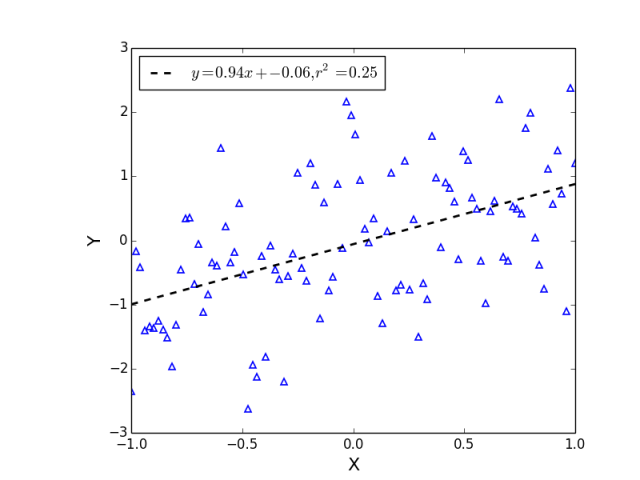
Linear regression is a fundamental machine learning algorithm used for predicting continuous values based on one or more input variables. Scikit-learn (sklearn), a popular Python library for machine learning, provides a simple and efficient implementation of linear regression through the LinearRegression class. In this comprehensive blog post, we will dive deep into sklearn linear regression, covering its theory, implementation, and practical examples.
What is Linear Regression?
Linear regression is a supervised learning algorithm that establishes a linear relationship between the independent variables (input variables, features, or predictors) and the dependent variable (output variable or target variable). The algorithm finds the best-fit line that minimizes the sum of squared errors between the predicted values and actual values. This line is called the regression line or best-fit line. The equation of this line is of the form : y=β0+β1∗x1+β2∗x2+...+βn∗xn where y is the dependent variable, x1, x2,..., xn are the independent variables, β0 is the intercept, and β1, β2,..., βn are the coefficients.
The goal of the Linear Regression algorithm is to estimate the values of these coefficients (β0, β1, β2,..., βn) in such a way that the sum of squared errors is minimized. This process is called the Ordinary Least Squares (OLS) method.
Sklearn LinearRegression Class
The scikit-learn library in Python implements Linear Regression through the LinearRegression class. This class allows us to fit a linear model to a dataset, predict new values, and evaluate the model's performance.To use the LinearRegression class, we first need to import it from the sklearn.linear_model module. We can then create an instance of the class and call its fit method to train the model on a dataset. Finally, we can use the prediction method to generate predictions on new data.
Here's an example of how to create a linear regression model using sklearn:
In addition to the basic Linear Regression algorithm, scikit-learn also provides algorithm variants that can handle more complex data, such as polynomial regression, ridge regression, and Lasso regression. These variants involve adding additional constraints or penalties to the model to prevent overfitting and improve its generalization performance.
Sklearn Linear Regression Prerequisites
Before working with linear regression in Scikit-learn (sklearn), it is important to have a basic understanding of the following concepts:
Linear algebra: Linear regression involves solving a system of linear equations, so it is important to have a basic understanding of linear algebra, including concepts such as matrices, vectors, and matrix multiplication.
Statistics: Understanding basic statistical concepts such as mean, variance, and the standard deviation is essential for working with linear regression models.
Python programming: Scikit-learn is a Python library, so a basic understanding of Python programming is necessary to work with it.
NumPy: NumPy is a fundamental package for scientific computing in Python and is used extensively in scikit-learn. It is important to have a basic understanding of NumPy arrays and operations.
Pandas: Pandas is another essential package for data manipulation and analysis in Python. It is used to read and preprocess data for use in scikit-learn.
Data visualization: It is important to visualize and explore data before building a linear regression model. Matplotlib and Seaborn are popular data visualization packages in Python.
Once you understand these concepts well, you can start learning and working with linear regression in Scikit-learn.
Sklearn Linear Regression Implementation
Let's go through the step-by-step process of implementing linear regression using sklearn:
Import the required libraries:
Load and preprocess the dataset:
Split the dataset into training and testing sets:
Create an instance of the LinearRegression class and fit the model:
Evaluate the model's performance:
Sklearn Linear Regression Evaluation Metrics
To evaluate the performance of a linear regression model, we can use various evaluation metrics. Some commonly used metrics in sklearn are:
Mean Squared Error (MSE):
Measures the average squared difference between the predicted values and actual values.
Lower values indicate better performance.
Can be calculated using the mean_squared_error function from sklearn.metrics.
Root Mean Squared Error (RMSE):
Square root of the MSE.
Provides the standard deviation of the unexplained variance.
Lower values indicate better performance.
Can be calculated by setting squared=False in the mean_squared_error function.
Mean Absolute Error (MAE):
Measures the average absolute difference between the predicted values and actual values.
Lower values indicate better performance.
Can be calculated using the mean_absolute_error function from sklearn.metrics.
R-squared (R²):
Measures the proportion of variance in the dependent variable that is predictable from the independent variables.
Values range from 0 to 1, with higher values indicating better performance.
Can be obtained using the score method of the LinearRegression class.
Here's an example of how to calculate these evaluation metrics in sklearn:
These evaluation metrics help us assess the quality of the linear regression model and compare its performance with other models or different configurations.
Sklearn Linear Regression Regularization
In some cases, linear regression models may suffer from overfitting, especially when dealing with high-dimensional data or a small number of samples. To mitigate this issue, sklearn provides regularization techniques that add a penalty term to the cost function. Two popular regularization methods in sklearn are:
Ridge Regression:
Adds an L2 regularization term to the cost function.
Shrinks the coefficients towards zero but never exactly to zero.
Can be used by setting the alpha parameter in the Ridge class from sklearn.linear_model.
Lasso Regression:
Adds an L1 regularization term to the cost function.
Performs feature selection by setting some coefficients exactly to zero.
Can be used by setting the alpha parameter in the Lasso class from sklearn.linear_model.
Here's an example of using Ridge Regression in sklearn:
Sklearn Linear Regression Limitations
While linear regression is a powerful and widely used algorithm, it has some limitations:
Linearity assumption: Linear regression assumes a linear relationship between the independent variables and the dependent variable. If the true relationship is non-linear, the model may not fit the data well.
Sensitivity to outliers: Linear regression is sensitive to outliers in the data, which can significantly influence the estimated coefficients. It is important to identify and handle outliers appropriately.
Multicollinearity: If the independent variables are highly correlated with each other, it can lead to unstable and unreliable coefficient estimates. Regularization techniques like Ridge and Lasso regression can help mitigate this issue.
Limited ability to capture complex relationships: Linear regression may not be able to capture complex, non-linear relationships between variables. In such cases, more advanced algorithms like decision trees, random forests, or neural networks may be more appropriate.
Assumption violations: If the assumptions of linear regression are violated (e.g., non-linearity, heteroscedasticity, non-normality), the model's results may be biased or unreliable. It is crucial to check these assumptions and address any violations.
Despite these limitations, linear regression remains a valuable tool in the machine learning arsenal, especially for its simplicity, interpretability, and ability to provide insights into the relationships between variables.
Sklearn Linear Regression Examples
Let's go through some practical examples of using sklearn linear regression:
Simple Linear Regression:
Predicting house prices based on the size of the house (in square feet).
Fitting a linear model to the training data and making predictions on the test data.
Evaluating the model's performance using MSE and R-squared.
Multiple Linear Regression:
Predicting car fuel efficiency (in miles per gallon) based on various features such as engine size, weight, and horsepower.
Fitting a multiple linear regression model to the training data.
Interpreting the coefficients and assessing the model's overall fit.
Polynomial Regression:
Predicting the stock price of a company based on the number of days since a certain event.
Transforming the input features to include polynomial terms (e.g., x, x^2, x^3).
Fitting a polynomial regression model and visualizing the non-linear relationship.
Ridge Regression:
Predicting the quality of wine based on various chemical properties.
Using Ridge Regression to handle multicollinearity and prevent overfitting.
Tuning the alpha parameter to find the optimal level of regularization.
Lasso Regression:
Predicting the energy efficiency of buildings based on various architectural features.
Applying
Lasso Regressionto perform feature selection and identify the most important predictors.Comparing the performance of Lasso Regression with other models.
These examples demonstrate the versatility of sklearn linear regression in handling different types of datasets and scenarios. By understanding the underlying concepts and applying the appropriate techniques, you can effectively use linear regression to solve a wide range of problems.
Conclusion
In this comprehensive blog post, we have explored the fundamentals of sklearn linear regression, including its theory, implementation, evaluation metrics, regularization techniques, and practical examples. Linear regression is a powerful and widely used machine learning algorithm that helps establish relationships between variables and make predictions.